
The learning science behind branching decisions, resource pressure, and the courage to let learners fail
In the companion article to this piece, I wrote about PATHFINDER — a mini-game designed to train cognitive flexibility through alien exploration. If you haven’t read that one yet, the short version: it’s a scenario-based game where the scoring rewards staying curious, not answering fast.

But this article isn’t about the game. It’s about why games like this work — and why the scenario mechanics I chose reflect something deeper about how humans actually learn critical thinking and advanced decision-making.
If you design training for a living, this is for you.
The Problem with “Choose the Right Answer”
Most scenario-based training follows a familiar pattern: present a situation, offer choices, reveal whether the learner picked correctly. It’s a quiz with better set dressing. The learner’s job is pattern recognition — match the situation to the “approved” response, collect your completion badge, move on.
This teaches compliance. It does not teach thinking.
The difference matters. Compliance-oriented training produces learners who can identify the correct answer in a training module. Thinking-oriented training produces people who can navigate situations the training designer never anticipated. One prepares people for the test. The other prepares people for the world.
The research backs this up. Cognitive load theory (Sweller), desirable difficulties (Bjork), and constructivist frameworks all point in the same direction: deeper learning happens when the learner is forced to construct understanding rather than select it. The struggle is the learning. Remove the struggle, and you’ve removed the mechanism.
Four Design Principles That Change Everything
When I built PATHFINDER, I made four deliberate design choices that deviate from standard scenario training. Each one is grounded in learning science, and each one is adaptable to corporate training contexts far from alien planets.
1. Multiple Valid Answers (Always)
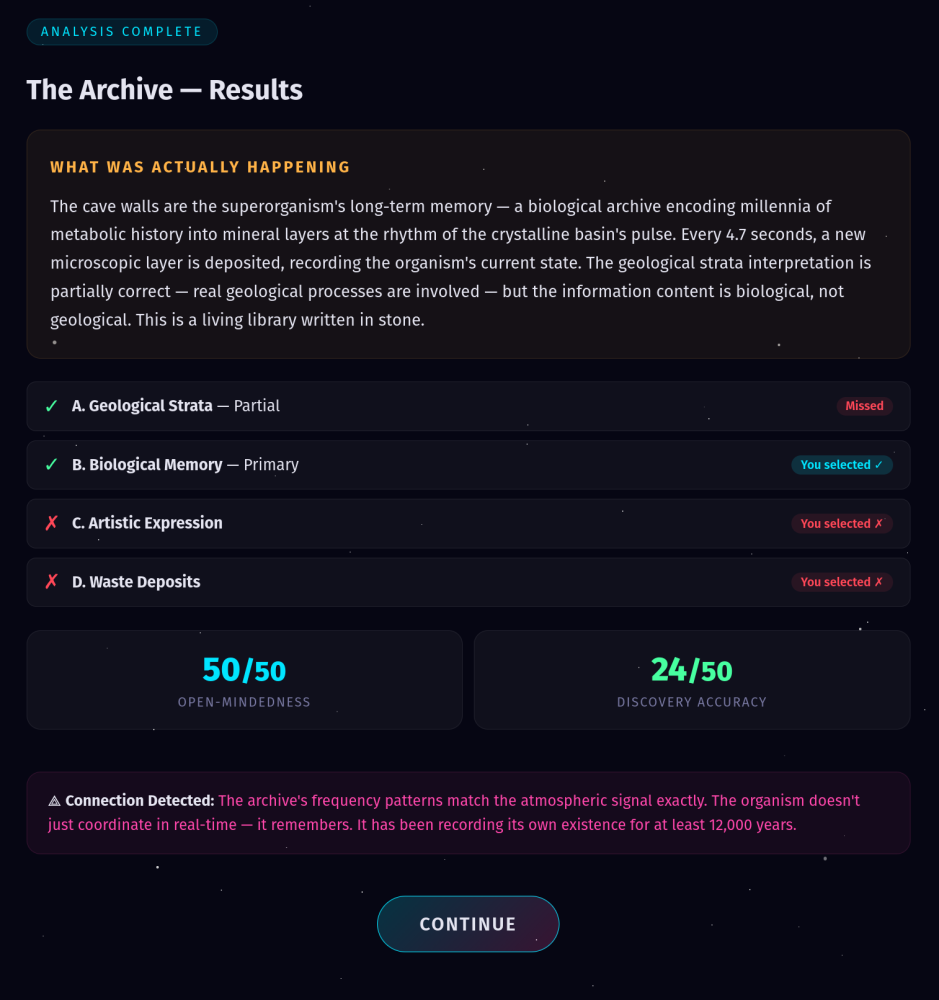
Every encounter in PATHFINDER has more than one correct answer. The crystalline basin? It’s a living organism (correct) AND the crystals resonate at natural harmonics (also correct) AND geological thermal processes are involved (partially correct). A player who picks just one explanation — even the “most” correct one — scores lower than someone who recognizes the full picture.
This is the single most important design choice in the entire system.
Real-world problems rarely have one correct answer. A customer complaint can be a product issue AND a communication failure AND a training gap, all at once. A market downturn can be driven by macroeconomic forces AND internal strategy AND competitive dynamics simultaneously. When we train people to pick *the* answer, we're training frame-lock — the very cognitive trap we should be dismantling.
The scoring in PATHFINDER reflects this: +20 points for each primary truth identified, +10 for partial truths, -8 for wrong selections, -12 for missing a primary truth entirely. The math rewards comprehensiveness over confidence. You want learners to think “what else might be true?” not “which one is it?“
2. Detractors That Actually Detract
In most training scenarios, evidence is additive. You get a piece of information, it points toward the right answer, you accumulate certainty. That’s not how real evidence works.
In PATHFINDER, every piece of evidence carries two tags: what it supports and what it challenges. The thermal scan supports both geological activity and biological life. The composition analysis supports biological life and crystal resonance — but challenges the geological explanation. Your mental model has to update and prune simultaneously.
This creates what Piaget called disequilibrium — that uncomfortable moment when new information doesn’t fit your existing schema. The instinct is to ignore the challenging data and cling to whatever you’ve already decided. That instinct is frame-lock. The training is in not doing that.
For corporate training design, this means your scenarios need evidence that genuinely complicates the learner’s model. Not trick questions — honest complexity. If a customer reports a bug, the diagnostic data should support and undermine multiple hypotheses. If a sales scenario presents competitive intelligence, it should challenge the rep’s assumptions about their own product’s strengths, not just confirm them.
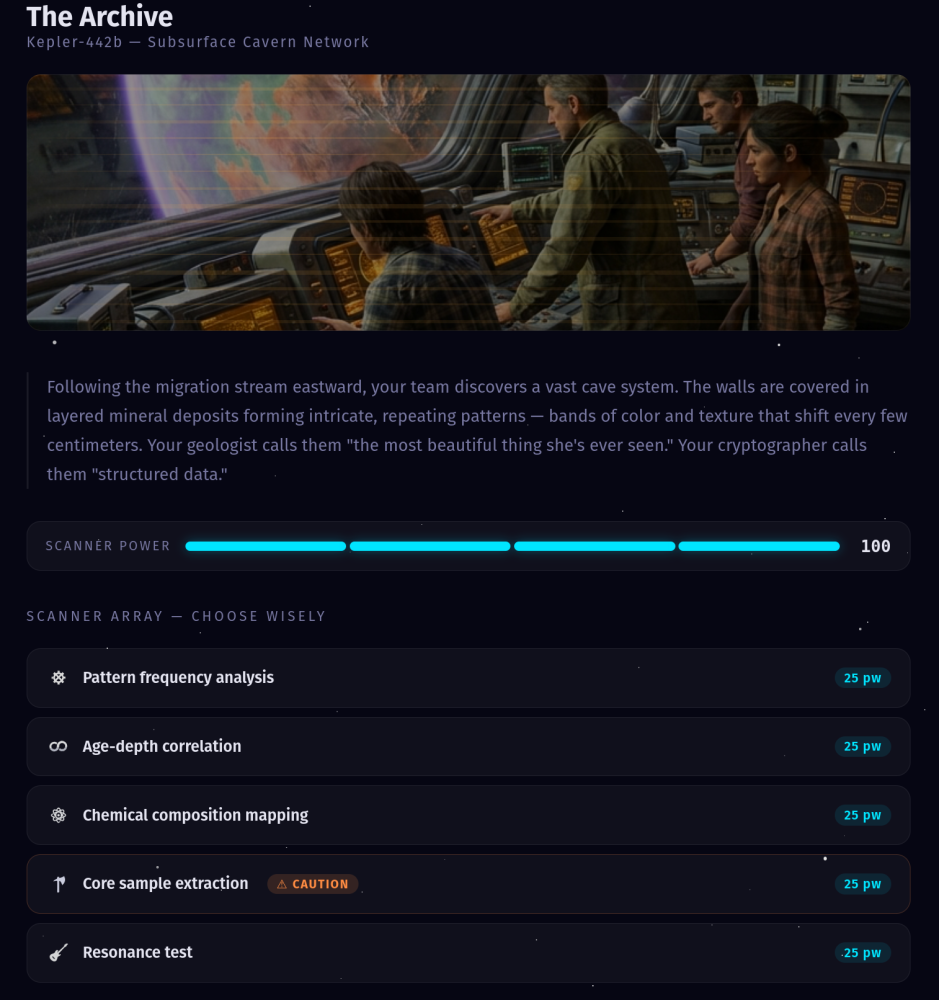
3. Limited Resources Force Prioritization
PATHFINDER gives you 100 energy units and five possible scans per encounter, each costing 25. You can only afford four. There is always one piece of evidence you don’t get to see.
This changes the entire cognitive posture of the learner. In a typical training scenario, you click every option, read everything, and then decide. There's no cost to thoroughness. But in the real world, every investigation has a budget. Every meeting has a time limit. Every diagnostic test costs money. Every question you ask a customer is a question you're *not* asking about something else.
Resource constraints force learners to develop judgment about what matters. Which scan do you skip? The risky one that might provoke the alien organism? The cross-reference that might connect two unrelated data points? There’s no right answer to that prioritization question — but making the choice and living with the consequences teaches something no amount of reading can.
When you design training, consider: what if the learner can’t see everything? What if they have to choose which three of five data sources to review before making a recommendation? The anxiety that produces — the “but what if I miss something?” feeling — is exactly the emotional state where real learning about prioritization happens.
4. Risky Actions With Real Consequences
Each encounter in PATHFINDER includes one “risky” scan. Before you run it, you get a warning: “High-powered sonar directed into the subsurface could disturb whatever is producing the pulse.” If you proceed, there’s a narrative consequence — the pulse falters, the organism knows you’re here, something has permanently changed.

The data from risky scans is always the most revealing. And the consequences are always irreversible. That’s the dilemma: the best information comes at the highest cost.
This mechanic teaches something that almost no corporate training addresses: the courage to act under uncertainty AND the wisdom to sometimes hold back. Not every stone should be turned. Not every question should be asked. Sometimes the smartest move is to preserve optionality — to keep the situation stable while you gather more information from safer sources.
In leadership training, this maps directly to difficult conversations, organizational restructuring, and strategic pivots. Yes, you could ask the direct question in the board meeting. The information would be valuable. But are you ready for the consequences of having asked it? That calculus — reward versus systemic risk — is one of the most valuable things a leader can practice in a safe environment.
The Metacognitive Layer: Measuring How You Think, Not Just What You Think
PATHFINDER scores along two axes, each worth 50 points. The first is Discovery Accuracy — did you identify what’s actually happening? That’s the content axis. Most training stops here.
The second axis is Open-Mindedness — measured by counting how many hypotheses the player keeps active (not dismissed) across all evidence reveals. If you dismiss three of four hypotheses after your first scan, your open-mindedness score craters regardless of whether your final answer is correct.
This is the metacognitive layer. It doesn’t just assess what the learner decided. It assesses how they decided — the process, not just the product. A player who gets the right answer through narrow, rigid thinking scores lower than a player who gets a partially right answer through genuinely open inquiry.
For training designers, this is a paradigm shift. We're accustomed to measuring outcomes: did the learner pass? Did they select the correct response? But if we want to build critical thinkers — people who can navigate novel situations — we need to measure the cognitive process. How long did they hold uncertainty before committing? Did they update their model when disconfirming evidence appeared? Did they resist the pull of the first plausible explanation?
These process metrics are harder to build into training systems, but they’re far more predictive of real-world performance than outcome metrics alone.
Building Your Own: The Creator Guide
I open-sourced PATHFINDER specifically so training designers could take these mechanics and apply them in their own domains. The GitHub repository ([github.com/increasinglyHuman/discovery](http://github.com/increasinglyHuman/discovery](https://github.com/increasinglyHuman/discovery))) includes a full creator guide that walks through encounter design, scoring psychology, and how to build scenarios that genuinely teach cognitive flexibility.
The architecture is intentionally modular. The game engine handles scoring, state management, energy mechanics, risk dialogs, and UI transitions. You supply the content: a JSON-like data structure defining your hypotheses, evidence items, truth mappings, and narrative text. Swap the alien planet for a cybersecurity incident response. Replace the scanner with a diagnostic toolkit. Turn the hexagonal columns into financial indicators. The cognitive mechanics transfer intact.
A few design principles from the creator guide that apply regardless of domain:
- Start with the truth, then work backwards. Decide what’s really happening in your scenario before you design hypotheses. The truth should be more complex than any single hypothesis captures. If the answer is clean and simple, the scenario won’t teach flexibility.
- Make the obvious answer wrong. If your scenario presents something that looks like ruins, the “someone built this” hypothesis should be present — and incorrect. The real answer should be stranger, more nuanced, more interesting. This teaches learners that their first instinct is a starting point, not a conclusion.
- Every hypothesis needs at least one piece of supporting evidence. No option should be obviously absurd. The learner needs to feel the genuine pull of each explanation. If three of four options are throwaway distractors, you’ve built a quiz, not a scenario.
- The risky action should yield the most informative data. This creates the authentic cost-benefit calculus that mirrors real decision-making. The best intelligence always comes at a price — that’s true whether you’re scanning alien organisms or deciding whether to commission an expensive market study.
The Bigger Point
We’re in a moment where every organization is talking about upskilling, reskilling, transformation, AI readiness, change management. The common thread in all of these is that people need to navigate situations that don’t have playbooks yet.
You can't write a procedure for the unprecedented. What you *can* do is train the cognitive muscle that handles novelty: the ability to hold multiple models, gather evidence without premature commitment, weigh costs and consequences, and make decisions under genuine uncertainty.
That’s what scenario-based training is for — not to rehearse the known, but to practice navigating the unknown. And the mechanics that make it work — multiple truths, real detractors, limited resources, consequential risk — aren’t just game design choices. They’re the structural requirements for building thinkers instead of test-takers.
The alien planet is optional. The cognitive flexibility is not.
Dr. Allen Partridge is Director of Product Evangelism at Adobe. He has spent 30+ years at the intersection of technology, education, and cognitive science, and believes the most important skill in an AI-transformed world is knowing how to hold competing ideas without your amygdala running the show.
Play PATHFINDER: https://poqpoq.com/adobe/pathfinder/
Fork the repo: https://github.com/increasinglyHuman/discovery
Creator guide: https://github.com/increasinglyHuman/discovery/blob/main/CREATING.md